Large Language Models (LLMs) are transforming industries, but unlocking their true potential often hinges on a critical challenge: connecting them to the outside world. Developers wanting to integrate models like Claude with specific company documents, live databases, or custom APIs faced a fragmented landscape. Each connection meant grappling with different APIs, authentication methods, and data formats – a messy, time-consuming puzzle of bespoke integrations. What if your AI could seamlessly access internal knowledge bases or trigger external tools without needing a custom-built bridge for every single one?
That’s the promise delivered by the Model Context Protocol (MCP). Born from the need for a unified approach, MCP introduces a standardized client-server architecture specifically designed for these interactions. It acts as a common language, defining how LLM applications can reliably discover and utilize external data sources (as ‘Resources’) and functionalities (as ‘Tools’). Forget the tangled web of custom connectors; MCP paves the way for building more powerful, context-aware AI applications by providing a single, consistent framework for bridging the gap between the LLM and your unique digital ecosystem. Ready to simplify your LLM integrations? Let’s dive in. In this article we will look at the core parts of MCP, including the Architecture, Resources, Tools, and more.
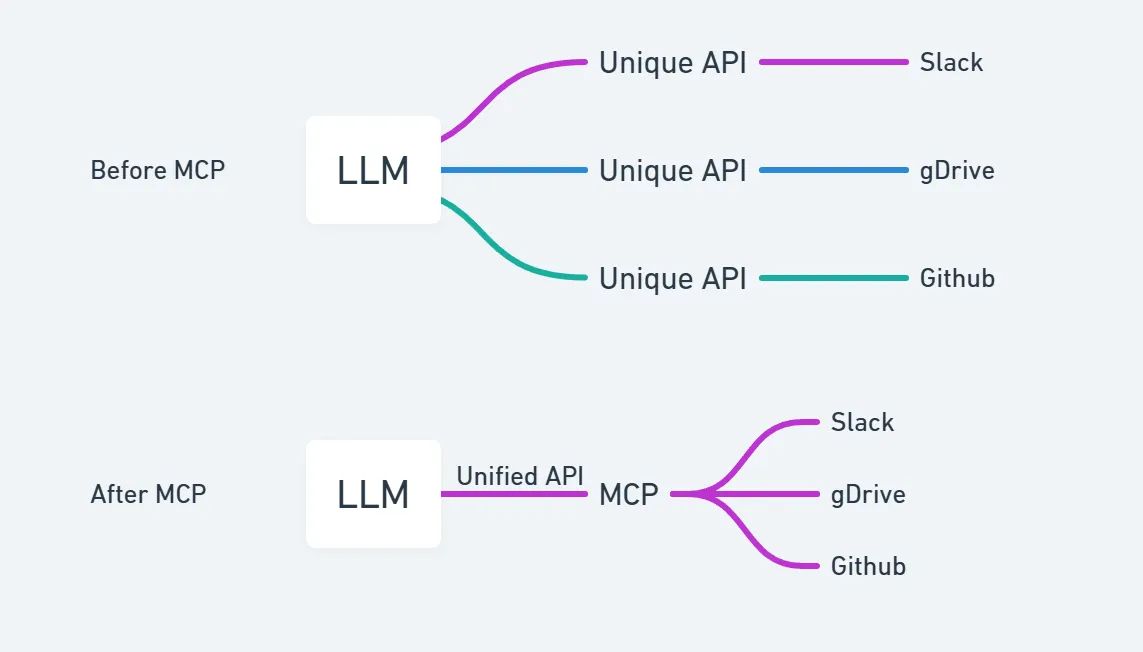
The Model Context Protocol (MCP) is a client-server architecture that facilitates communication between LLM applications and integrations.
Generally, a host (chat app) has multiple clients. Each of these clients is a link to a server running code that does something (api calls, data retrieval, etc…).
A single host can have many clients, each linking to a server with multiple tools or resources. It is a standardised way of linking AI models to the world. The following is more technical details about the various aspects that make MCP work.
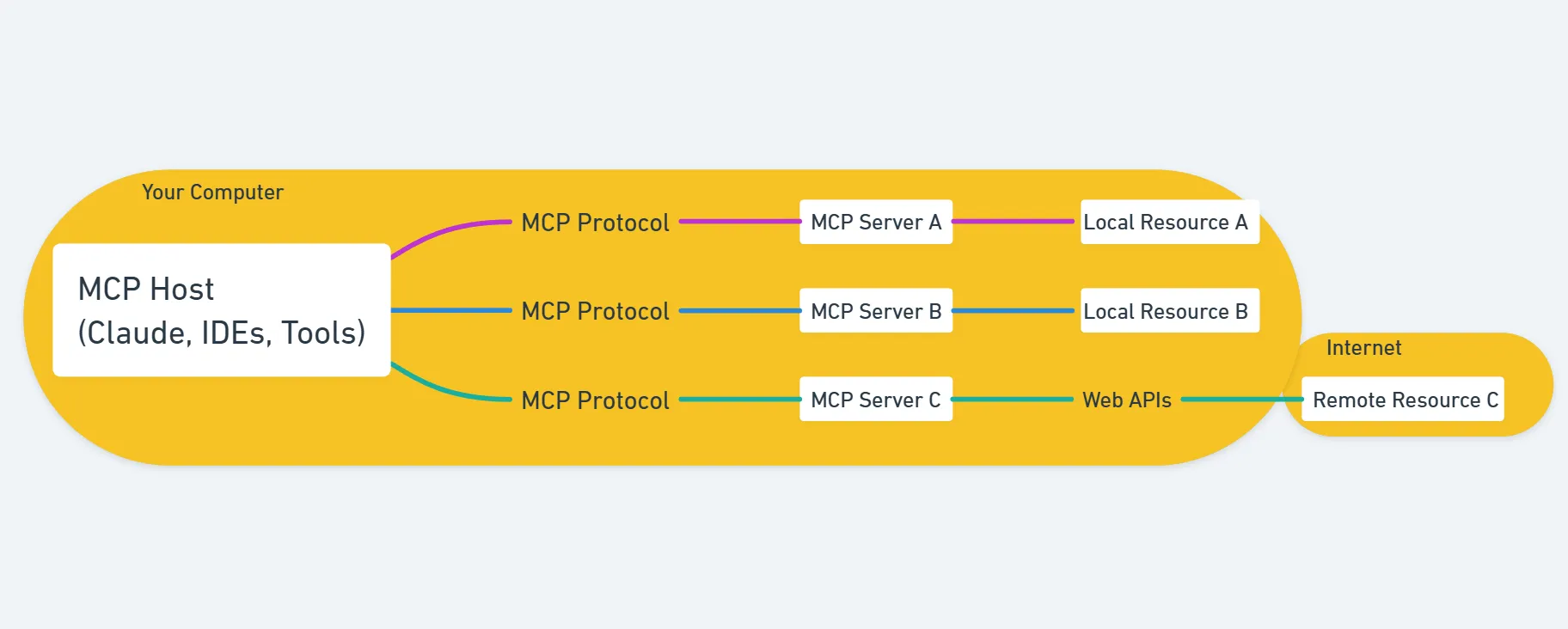
Architecture Overview:
There are a few layers that make this work.
Protocol Layer:
Transport Layer supports two mechanisms:
All transports use JSON-RPC 2.0 format.
Message Types:
initialize request with protocol version and capabilitiesinitialized notification as acknowledgmentclose()Standard error codes include ParseError, InvalidRequest, MethodNotFound, InvalidParams, and InternalError.
import { Server } from "@modelcontextprotocol/sdk/server/index.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
const server = new Server({
name: "example-server",
version: "1.0.0"
}, {
capabilities: {
resources: {}
}
});
// Handle requests
server.setRequestHandler(ListResourcesRequestSchema, async () => {
return {
resources: [
{
uri: "example://resource",
name: "Example Resource"
}
]
};
});
// Connect transport
const transport = new StdioServerTransport();
await server.connect(transport);import asyncio
import mcp.types as types
from mcp.server import Server
from mcp.server.stdio import stdio_server
app = Server("example-server")
@app.list_resources()
async def list_resources() -> list[types.Resource]:
return [
types.Resource(
uri="example://resource",
name="Example Resource"
)
]
async def main():
async with stdio_server() as streams:
await app.run(
streams[0],
streams[1],
app.create_initialization_options()
)
if __name__ == "__main__":
asyncio.run(main())Transport Selection:
Message Handling:
Resources are a core primitive in the Model Context Protocol that allow servers to expose data and content for LLM interactions.
The model will decide when to use specific resources based on the context of the conversation, the user’s needs, and the resource availability as defined by the server. Resources can include log files, text documents, and more. The following is the technical details that make it work.
Overview:
Resource URIs:
[protocol]://[host]/[path]file:///home/user/documents/report.pdf, postgres://database/customers/schemaThere are two types of resources.
Resource Types:
There are direct resources and resource templates, for different types of resources (static and dynamic). See toggles for details.
resources/list endpoint.
Each includes: uri, name, optional description, optional mimeType.{
uri: string; // Unique identifier for the resource
name: string; // Human-readable name
description?: string; // Optional description
mimeType?: string; // Optional MIME type
}{
uriTemplate: string; // URI template following RFC 6570
name: string; // Human-readable name for this type
description?: string; // Optional description
mimeType?: string; // Optional MIME type for all matching resources
}resources/read request with URI{
contents: [
{
uri: string; // The URI of the resource
mimeType?: string; // Optional MIME type
// One of:
text?: string; // For text resources
blob?: string; // For binary resources (base64 encoded)
}
]
}Resource Updates:
notifications/resources/list_changedresources/subscribe with URInotifications/resources/updated when resource changesresources/readresources/unsubscribeconst server = new Server({
name: "example-server",
version: "1.0.0"
}, {
capabilities: {
resources: {}
}
});
// List available resources
server.setRequestHandler(ListResourcesRequestSchema, async () => {
return {
resources: [
{
uri: "file:///logs/app.log",
name: "Application Logs",
mimeType: "text/plain"
}
]
};
});
// Read resource contents
server.setRequestHandler(ReadResourceRequestSchema, async (request) => {
const uri = request.params.uri;
if (uri === "file:///logs/app.log") {
const logContents = await readLogFile();
return {
contents: [
{
uri,
mimeType: "text/plain",
text: logContents
}
]
};
}
throw new Error("Resource not found");
});app = Server("example-server")
@app.list_resources()
async def list_resources() -> list[types.Resource]:
return [
types.Resource(
uri="file:///logs/app.log",
name="Application Logs",
mimeType="text/plain"
)
]
@app.read_resource()
async def read_resource(uri: AnyUrl) -> str:
if str(uri) == "file:///logs/app.log":
log_contents = await read_log_file()
return log_contents
raise ValueError("Resource not found")
# Start server
async with stdio_server() as streams:
await app.run(
streams[0],
streams[1],
app.create_initialization_options()
)When using resources:
Prompts are predefined templates for interactions with the model. The are reusable instructions that tell a language model (or LLM) how to perform a task. Think of them as templates or blueprints that can be filled in with specific details. They help standardize the way common interactions are performed between the server, client, and the language model.
User-Controlled: Prompts are designed so that users have control. They are made available by servers and can be explicitly chosen by the user for certain tasks.
Common use cases of prompts are summarize or analize code.
{
name: string; // Unique identifier for the prompt
description?: string; // Human-readable description
arguments?: [ // Optional list of arguments
{
name: string; // Argument identifier
description?: string; // Argument description
required?: boolean; // Whether argument is required
}
]
}Clients can discover available prompts through the prompts/list endpoint:
prompts/list endpoint.prompts/get endpoint with:
Using prompts
prompts/get request// Request
{
method: "prompts/get",
params: {
name: "analyze-code",
arguments: {
language: "python"
}
}
}
// Response
{
description: "Analyze Python code for potential improvements",
messages: [
{
role: "user",
content: {
type: "text",
text: "Please analyze the following Python code for potential improvements:\n\n```python\ndef calculate_sum(numbers):\n total = 0\n for num in numbers:\n total = total + num\n return total\n\nresult = calculate_sum([1, 2, 3, 4, 5])\nprint(result)\n```"
}
}
]
}Dynamic prompts: Prompts can be dynamic and include: Embedded resource context, Multi-step workflows
Prompts can be directly integrated into the user interface:
Tools are a powerful primitive in the Model Context Protocol that enable servers to expose executable functionality to clients. They are model-controlled, allowing AI models to automatically invoke them (sometimes with human approval) to interact with external systems, perform computations, and take actions. The following is a list of some potential capabilities of tools:
{
name: string; // Unique identifier
description?: string; // Human-readable description
inputSchema: { // JSON Schema for parameters
type: "object",
properties: { ... }
},
annotations?: { // Optional behavior hints
title?: string; // Human-readable title
readOnlyHint?: boolean; // If true, doesn't modify environment
destructiveHint?: boolean; // If true, may perform destructive updates
idempotentHint?: boolean; // If true, repeated calls have no additional effect
openWorldHint?: boolean; // If true, interacts with external entities
}
}How does MCP look in practice? Let’s look into specific, varied use cases where MCP shines, ranging from enterprise integrations to developer tools to AI agents.
Use Case: A multinational corporation wants its internal LLM assistant to access its knowledge base containing company manuals, HR policies, and compliance documents.
How MCP helps:
resources/list and resources/read endpoints.Use Case: Building a coding assistant inside VSCode that can: Access project files, Search through logs, Deploy services via CLI commands
How MCP helps:
Use Case: A lab assistant AI helps researchers by: Fetching the latest published papers, Running analysis scripts, Summarizing experiment results
How MCP helps:
Use Case: Automating tasks for an e-commerce operator, like: Price comparisons, Stock monitoring, Auto-listing new products
How MCP helps:
Integrating Large Language Models with diverse external data sources and functionalities has historically presented a significant hurdle. Developers faced not only the burden of creating complex, custom-built solutions for each connection but also substantial rework when attempting to switch between different LLMs like ChatGPT, Claude, or Grok, as each integration was often model-specific. Moreover, adding or removing capabilities frequently involved the cumbersome task of managing different APIs and bespoke integration logic, lacking a consistent approach. The Model Context Protocol (MCP) directly confronts these specific interoperability and maintenance challenges by introducing a crucial, unified standard. As explored throughout this article, MCP establishes a robust client-server architecture and defines clear primitives – Resources for seamless data access, Tools for invoking external actions, and Prompts for reusable interaction templates – providing the standardized foundation that was previously missing.
This standardization creates a common language, moving away from the fragmented landscape of bespoke integrations towards a more streamlined, scalable, and developer-friendly approach. By providing defined protocols, transport mechanisms, discovery methods, and clear structures for these components, MCP significantly simplifies the process of bridging the gap between LLMs and the specific digital ecosystems they need to interact with. The practical implementation examples provided demonstrate how developers can leverage MCP using SDKs in languages like TypeScript and Python to easily expose data and functionality in a reusable way.
In essence, mastering the concepts within the Model Context Protocol equips us with the understanding of a crucial abstraction layer for modern AI development. We’ve learned that MCP isn’t just another way to connect LLMs to external systems; it’s a standardized blueprint designed to improve the inherent complexity and previously fragmented nature of these integrations. This knowledge is critically important because it signals a significant shift towards greater interoperability, reusability, and efficiency. By providing this common language and structure for Resources, Tools, and Prompts, MCP empowers developers not only to build more sophisticated connections faster but also fosters an ecosystem where capabilities can be more easily shared and leveraged across different AI applications, ultimately accelerating the pace at which AI can be meaningfully integrated into diverse workflows and systems.
The Model Context Protocol (MCP) represents a pivotal advancement in AI development, enabling models to seamlessly connect with diverse systems and data sources. This integration marks the next step in advancing AI models, connecting them with access to various systems, and fostering a more interoperable and efficient ecosystem.
Using MCP Tools in Chatbot
MCP Sampling
MCP Roots
MCP Transport
MCP Inspector
Introducing the Model Context Protocol - Anthropic
Model Context Protocol Documentation - Anthropic