Large language models (LLMs) have come a long way—from just generating text to now reasoning, planning, and taking actions. As these capabilities grow, so does the interest in using LLMs as agents: autonomous systems that can interact with the world, make decisions, and complete complex tasks. From navigating websites and manipulating files to querying databases and playing games, LLM agents are becoming central to a wide range of real-world AI applications.
As these capabilities grow, so does the need to rigorously evaluate them. Benchmarks provide structured, measurable ways to assess how well LLM agents perform across different domains like web environments, tool use, planning, and reasoning.
In this blog, we’ll walk through some of the most widely used and influential benchmarks for evaluating LLM agents, breaking down what they measure, how they work, and what makes each of them unique.
LLM agents are systems powered by large language models designed to interact with external tools or systems, such as databases, websites, and games, to accomplish specific goals. They combine reasoning, planning, and execution by analyzing problems, formulating solutions, and carrying them out through actions like generating function calls, crafting API requests, or providing text instructions for simulated tasks (e.g., clicks on a website).
Potential tasks for LLM agents could include scenarios like “find the cheapest flight from New York to London,” where the agent queries a flight database and executes the solution by generating API requests to retrieve flight options. Other examples involve tasks such as “navigate a website to complete an online purchase” or “analyze data from a database to generate a report.”

For an LLM to work effectively as an agent, it needs to have strong reasoning capabilities and the ability to generate accurate code or function calls with the correct parameters. This makes benchmarks essential for evaluating how well LLMs perform in these areas, helping us understand their strengths and limitations when acting as autonomous agents.
| Benchmark | Evaluation Aspect | Description | Evaluation method |
|---|---|---|---|
| AgentBench | Language understanding, Planning, Reasoning, Decision making, Tool-calling, Multi-turn | Evaluates LLM agents across various real-world agent tasks (e.g., browsing, coding, KG querying). | Success rates, reward scores, F1 score, etc… |
| AgentBoard | Planning, Reasoning, Tool-calling, Language understanding, Decision making, Multi-turn | Evaluates LLM agents in complex, multi-turn tasks across physical, game, web, and tool-based environments. | Step-by-step evaluation (fine-grained progress rate, task completion rate) |
| Berkeley Function Calling Leaderboard Benchmark | Tool-calling | Focuses on structured function-call generation | AST matching, output correctness, API response structure |
| GAIA | Reasoning, Multi-modality handling, Web browsing, Tool-calling, Multi-turn | Evaluates AI assistants’ ability to reason, browse the web, and use multiple tools across various tasks. | Quasi Exact Match |
| Stable ToolBench | Tool-calling (Multi-tool Scenarios) | Evaluates tool-augmented agents in stable, reproducible virtual API settings, including multi-tool use. | Pass rate, win rate |
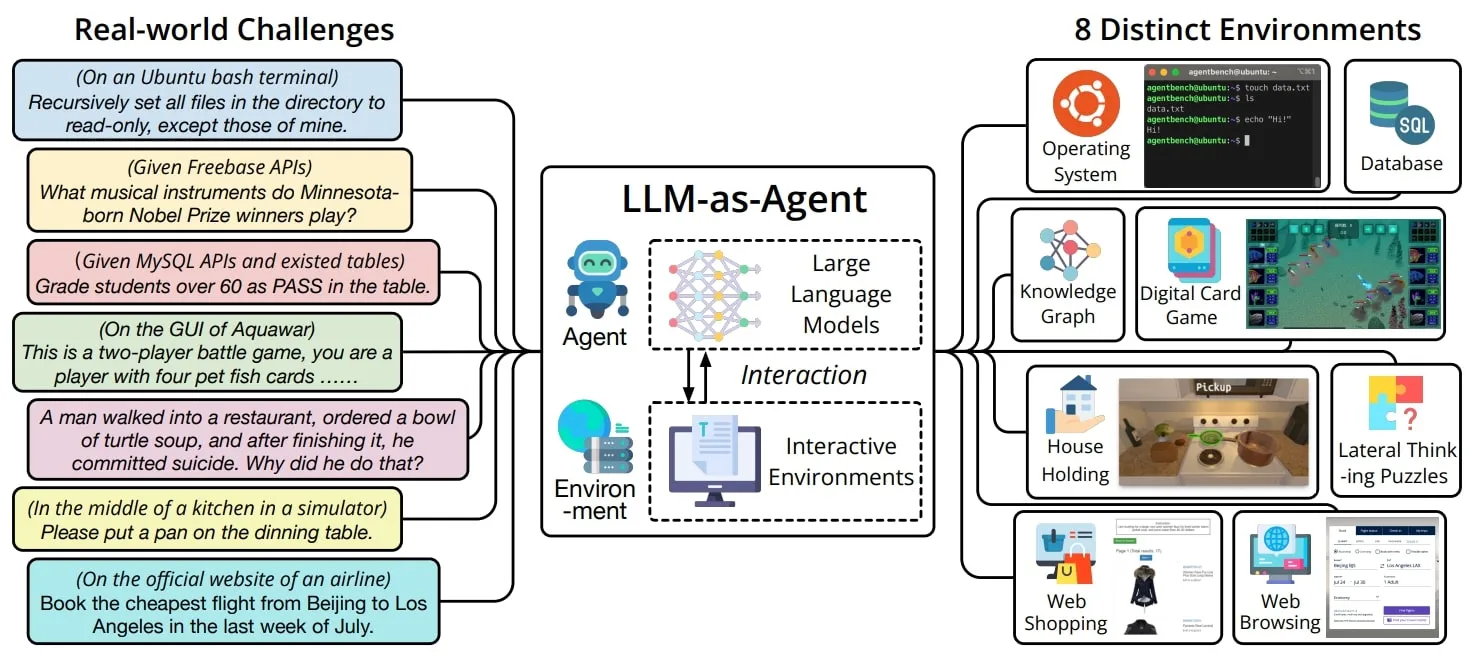
AgentBench, introduced in the 2023 paper “AgentBench: Evaluating LLMs as Agents”, evaluates the reasoning, decision-making, and task execution capabilities of LLMs across eight open-ended, multi-turn task environments. These environments are designed to test various aspects of agentic performance, such as language understanding, planning, and tool interaction.
The benchmark focuses on three main domains: code, games, and the web. In more detail, these environments are:
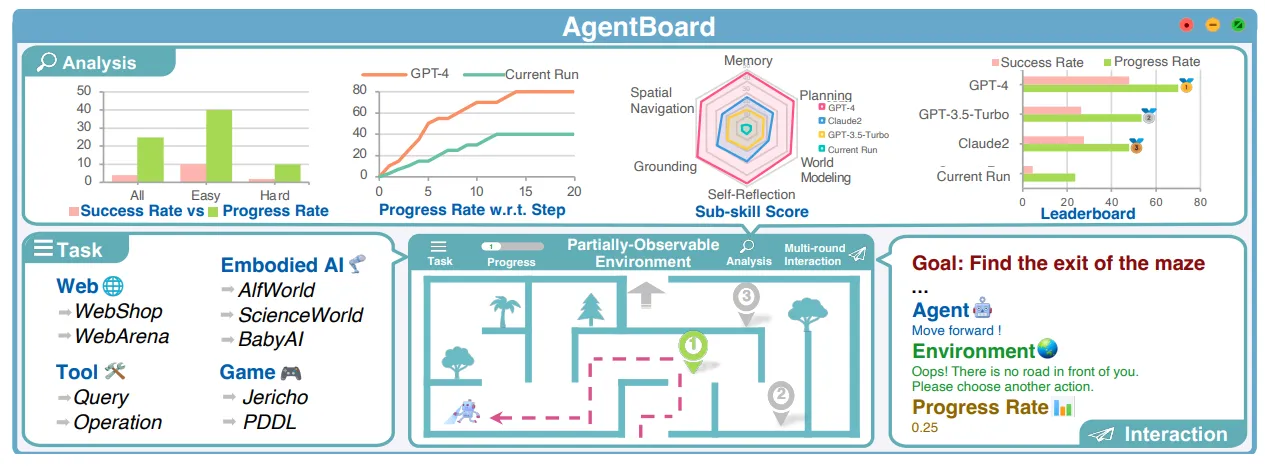
AgentBoard was introduced in the 2024 paper, “AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents”.
Like AgentBench, it’s a multi-faceted benchmark. AgentBoard covers four main domains—embodied (test agents in simulated physical environments), game, web, and **tool (**evaluate the agent’s use of external tools).
Unlike many other benchmarks, AgentBoard uses a fine-grained progress rate to capture step-by-step performance rather than just final outcomes. This metric standardizes evaluation across diverse task types, enabling more meaningful comparisons and averaging.
Check out the AgentBoard leaderboard here.
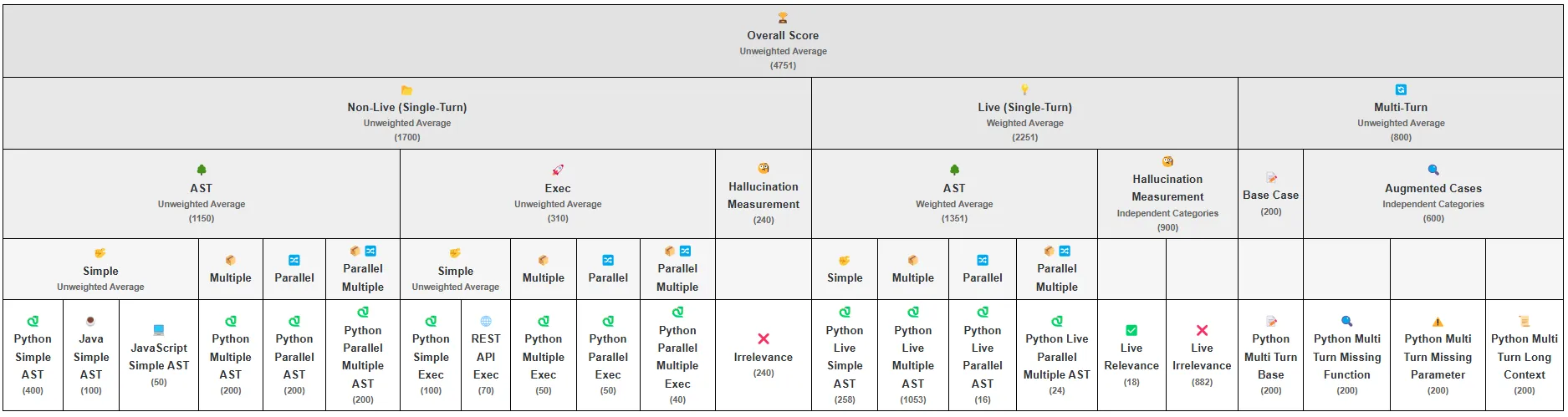
The latest version of the Berkeley Function Calling Leaderboard (BFCL) was introduced in the 2024 blog post, “Gorilla: Large Language Model Connected with Massive APIs” by researchers from UC Berkeley.
Sourced from real-world user data, BFCL includes 4,751 tasks across function calling, REST APIs, SQL, and function relevance detection. Most tasks use Python, with some in Java and JavaScript to assess generalization. Tasks are single-turn or multi-turn, and multi-turn problems are split into base and augmented variants—the latter introducing challenges like missing parameters, missing functions, or long context.
Check out the BFCL leaderboard here.
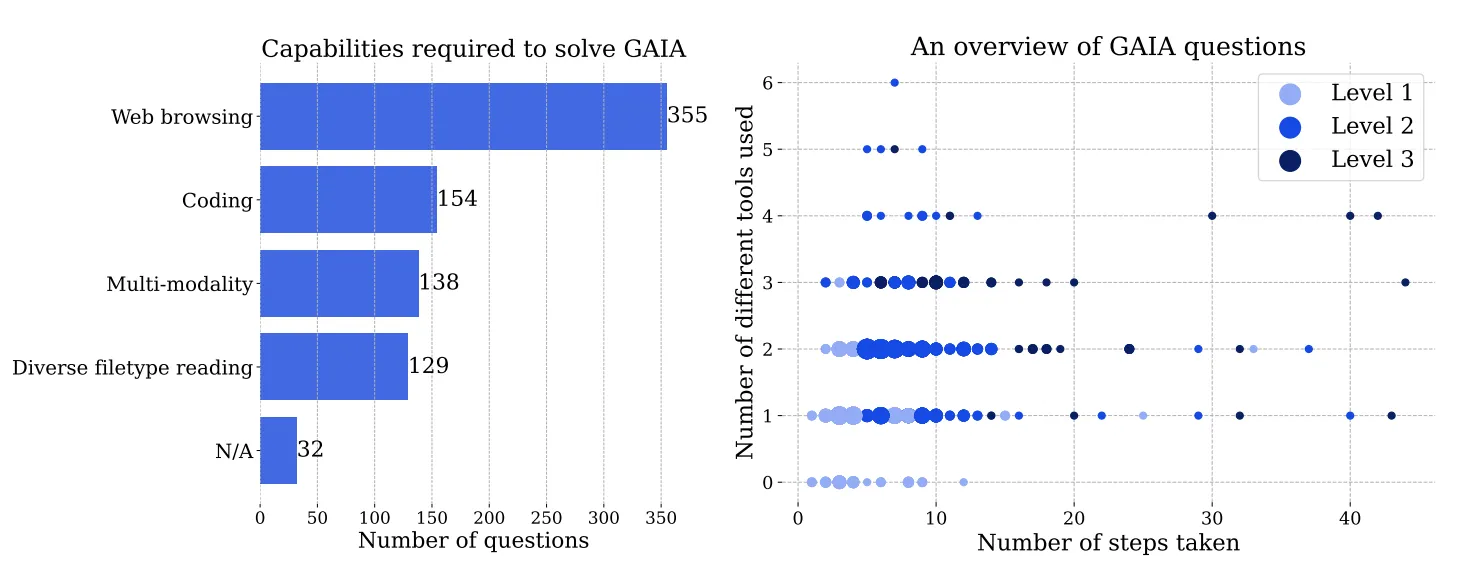
GAIA (A Benchmark for General AI Assistants) was introduced in the 2023 paper, “GAIA: A Benchmark for General AI Assistants” by researchers from Meta, Huggingface, and AutoGPT. It presents real-world questions designed to test an AI assistant’s ability to reason, use tools, handle multiple modalities, and browse the web—tasks that are easy for humans but remain challenging for AI.
GAIA covers five core capabilities: web browsing, multimodal understanding (e.g., speech, video, image), code execution, diverse file reading (e.g., PDFs, Excel), and tasks solvable without tools (e.g., translations or spell-checking).
Each GAIA question has a single correct answer in a simple format (e.g., a string, number, or comma-separated list), and tasks are grouped into three difficulty levels:
Check out the GAIA leaderboard here.
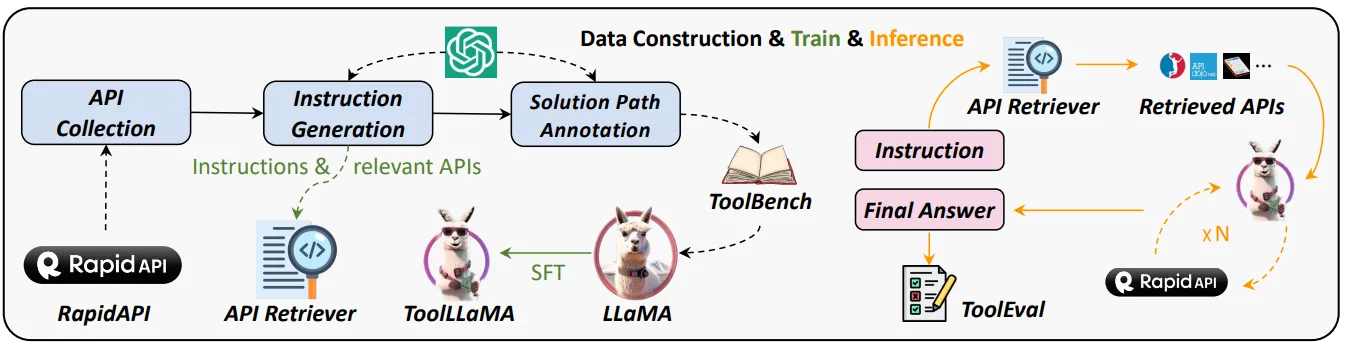
Stable ToolBench is an updated benchmark built upon ToolBench, introduced in the 2025 paper, “StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models” by researchers from Tsinghua University, 01.AI, Google, the University of Hong Kong, and the Jiangsu Innovation Center for Language Competence.
The benchmark employs virtual APIs within a controlled system to ensure stability and reproducibility. LLMs simulate API behaviors by first querying the cache of real API calls. If the requested behavior is not found in the cache (a cache miss), the system then returns simulated output using documentation and few-shot real API calls to replicate the API’s response.
The dataset consists of instructions generated from collected APIs for both single-tool and multi-tool scenarios, assessing an LLM’s ability to interact with individual tools and combine them for complex task completion.
Evaluations on this benchmark focus on two key metrics: the pass rate, which gauges an LLM’s ability to execute an instruction within set budgets, and the win rate, which compares the quality of the LLM’s solution path to that generated by gpt-3.5-turbo.
Here are several other notable benchmarks designed to evaluate various aspects of LLM performance across different domains and task types:
In conclusion, the expanding landscape of benchmarks for evaluating large language models (LLMs) has introduced a variety of tasks designed to test critical capabilities such as function calling, multi-step reasoning, and tool integration. These benchmarks are crucial for assessing LLM performance in different contexts, pushing the boundaries of what these models can achieve in real-world scenarios. From evaluating their ability to handle simple tasks to more complex, multi-domain challenges, they play a key role in guiding future advancements.
As LLMs continue to evolve, these benchmarks remain essential for providing insights into model strengths and weaknesses. They offer a clearer understanding of how well LLMs can interact with tools, databases, and diverse problem domains, ensuring that their development leads to more reliable and effective models for practical applications.
GAIA: A Benchmark for General AI Assistants
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting
Tau-Bench: A Benchmark for Evaluating LLM-based Agents for Multi-step Reasoning
AgentBench: Evaluating LLMs as Agents
AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents
ToolACE: Winning the Points of LLM Function Calling